在求解机器学习算法的模型参数,即无约束优化问题时,梯度下降(Gradient Descent)是最常采用的方法之一,另一种常用的方法是最小二乘法。这里就对梯度下降法做一个完整的总结。
BGD 批量梯度下降算法
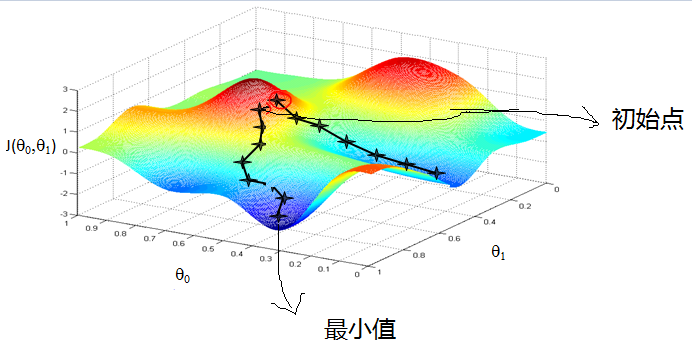
首先来看看梯度下降的一个直观的解释。比如我们在一座大山上的某处位置,由于我们不知道怎么下山,于是决定走一步算一步,也就是在每走到一个位置的时候,求解当前位置的梯度,沿着梯度的负方向,也就是当前最陡峭的位置向下走一步,然后继续求解当前位置梯度,向这一步所在位置沿着最陡峭最易下山的位置走一步。这样一步步的走下去,一直走到觉得我们已经到了山脚。当然这样走下去,有可能我们不能走到山脚,而是到了某一个局部的山峰低处。
从上面的解释可以看出,梯度下降不一定能够找到全局的最优解,有可能是一个局部最优解。当然,如果损失函数是凸函数,梯度下降法得到的解就一定是全局最优解。
梯度下降的相关概念

算法的具体过程可以见下图:

BGD最关键的地方在于理解,为什么梯度参数更新的时候用原参数 - 损失函数关于参数的偏导数。因为函数关于某一点的导数的意义在于这一点的变化率,那么关于参数的导数就是参数的变化率,而乘以步长的意义在于参数变化了多少。

那么我们可以看到,每更新一次参数就要用到所有的训练数据,这样的话是非常耗时的。
SGD Stochastic Gradient Descent 随机梯度下降算法
由于批梯度下降每跟新一个参数的时候,要用到所有的样本数,所以训练速度会随着样本数量的增加而变得非常缓慢。随机梯度下降正是为了解决这个办法而提出的。它是利用每个样本的损失函数对θ求偏导得到对应的梯度,来更新θ:

也就是说在SGD中,算法不再考虑每个样本的意见了,而是见好就收,针对当前样本进行上文所述的修正。显而易见的,这种方法在速度上取得了绝对的优势,但是在收敛性上显得过于随意。随机梯度下降是通过每个样本来迭代更新一次,对比上面的批量梯度下降,迭代一次需要用到所有训练样本(往往如今真实问题训练数据都是非常巨大),一次迭代不可能最优,如果迭代10次的话就需要遍历训练样本10次。但是,SGD伴随的一个问题是噪音较BGD要多,使得SGD并不是每次迭代都向着整体最优化方向。
MBGD Mini-batch Gradient Descent
上面两种算法各有优缺点,而MBGD就是中和了上面两种方法的,也就是说我们更新参数的时候,能够自己选择使用样本的个数

总结
批梯度下降每次更新使用了所有的训练数据,最小化损失函数,如果只有一个极小值,那么批梯度下降是考虑了训练集所有数据,是朝着最小值迭代运动的,但是缺点是如果样本值很大的话,更新速度会很慢。
随机梯度下降在每次更新的时候,只考虑了一个样本点,这样会大大加快训练数据,也恰好是批梯度下降的缺点,但是有可能由于训练数据的噪声点较多,那么每一次利用噪声点进行更新的过程中,就不一定是朝着极小值方向更新,但是由于更新多轮,整体方向还是大致朝着极小值方向更新,又提高了速度。
小批量梯度下降法是为了解决批梯度下降法的训练速度慢,以及随机梯度下降法的准确性综合而来,但是这里注意,不同问题的batch是不一样的,听师兄跟我说,我们nlp的parser训练部分batch一般就设置为10000,那么为什么是10000呢,我觉得这就和每一个问题中神经网络需要设置多少层,没有一个人能够准确答出,只能通过实验结果来进行超参数的调整。