以前spark-streaming用的比较多,ML库用的比较少,对pipeline之类的概念理解的不够深入。趁清明假期总结一下,温故知新。
spark提供的标准的机器学习算法能够将不同的算法和组件组合在一起,形成一个管道或者工作流。可以参考代码来看: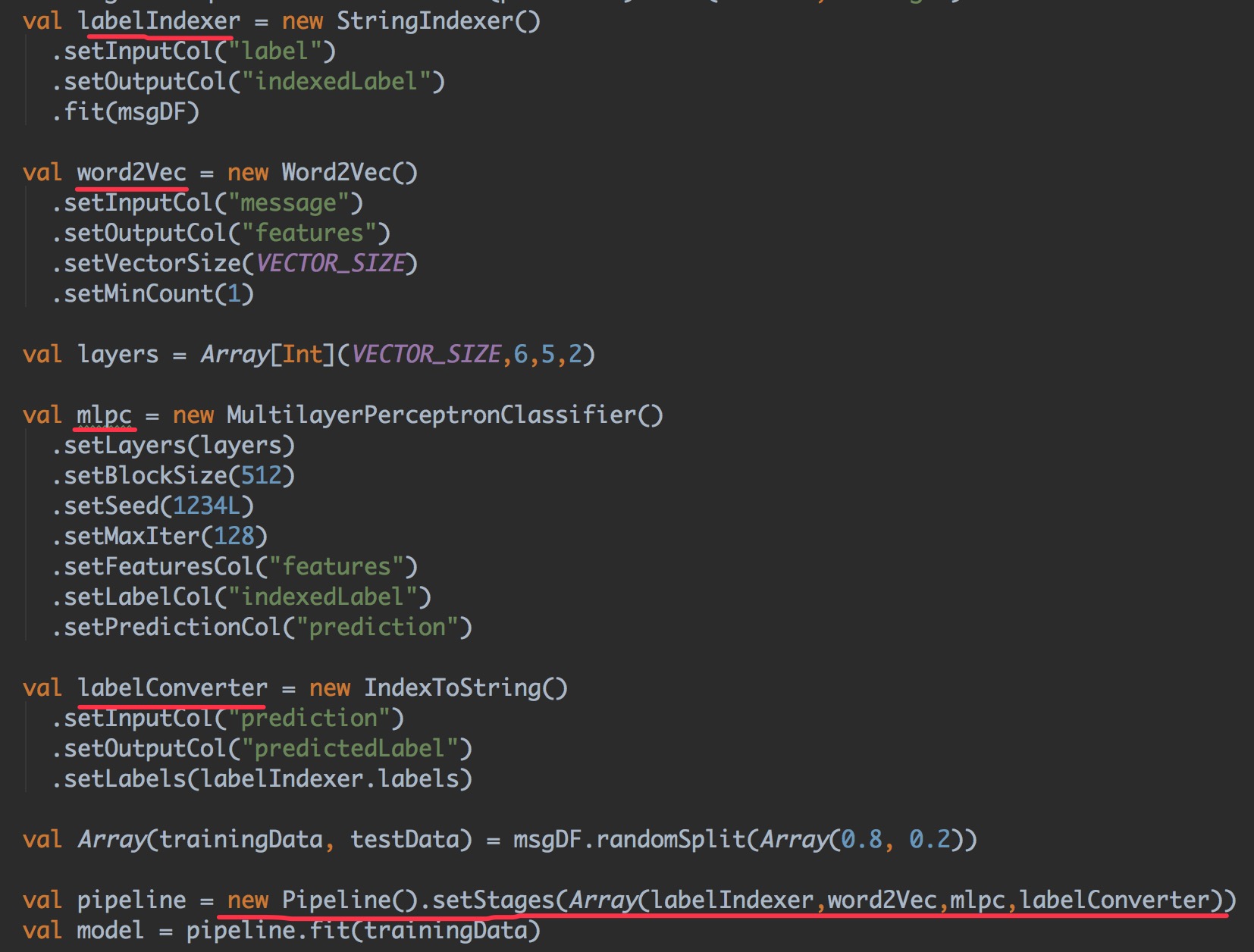
可以看到pipeline可以顾名思义地理解为管道,将所有的算法和配置组建起来。MLlib对机器学习算法的API进行了标准化,使得将多种算法合并成一个pipeline或工作流变得更加容易。Pipeline的概念主要是受scikit-learn启发。接下来解释一下各个细节: