目前中文分词三大主流分词方法:基于词典的方法、基于规则的方法和基于统计的方法
基于词典的方法
1 | 定义:按照一定策略将待分析的汉字串与一个“大机器词典”中的词条进行匹配,若在词典中找到某个字符串,则匹配成功。 |
- 按照扫描方向的不同:正向匹配和逆向匹配
- 按照长度的不同:最大匹配和最小匹配
正向最大匹配思想MM
- 从左向右取待切分汉语句的m个字符作为匹配字段,m为大机器词典中最长词条个数。
- 查找大机器词典并进行匹配:
- 若匹配成功,则将这个匹配字段作为一个词切分出来。
- 若匹配不成功,则将这个匹配字段的最后一个字去掉,剩下的字符串作为新的匹配字段,进行再次匹配,重复以上过程,直到切分出所有词为止。
举个栗子:
现在,我们要对“南京市长江大桥”这个句子进行分词,根据正向最大匹配的原则:
- 先从句子中拿出前5个字符“南京市长江”,把这5个字符到词典中匹配,发现没有这个词,那就缩短取字个数,取前四个“南京市长”,发现词库有这个词,就把该词切下来;
- 对剩余三个字“江大桥”再次进行正向最大匹配,会切成“江”、“大桥”;
- 整个句子切分完成为:南京市长、江、大桥;
逆向最大匹配算法RMM
该算法是正向最大匹配的逆向思维,匹配不成功,将匹配字段的最前一个字去掉,实验表明,逆向最大匹配算法要优于正向最大匹配算法。
还是那个栗子:
- 取出“南京市长江大桥”的后四个字“长江大桥”,发现词典中有匹配,切割下来;
- 对剩余的“南京市”进行分词,整体结果为:南京市、长江大桥
双向最大匹配法(Bi-directction Matching method,BM)
双向最大匹配法是将正向最大匹配法得到的分词结果和逆向最大匹配法的到的结果进行比较,从而决定正确的分词方法。
据SunM.S. 和 Benjamin K.T.(1995)的研究表明,中文中90.0%左右的句子,正向最大匹配法和逆向最大匹配法完全重合且正确,只有大概9.0%的句子两种切分方法得到的结果不一样,但其中必有一个是正确的(歧义检测成功),只有不到1.0%的句子,或者正向最大匹配法和逆向最大匹配法的切分虽重合却是错的,或者正向最大匹配法和逆向最大匹配法切分不同但两个都不对(歧义检测失败)。这正是双向最大匹配法在实用中文信息处理系统中得以广泛使用的原因所在。
还是那个栗子:
双向的最大匹配,即把所有可能的最大词都分出来,上面的句子可以分为:南京市、南京市长、长江大桥、江、大桥
设立切分标志法
收集切分标志,在自动分词前处理切分标志,再用MM、RMM进行细加工。
最佳匹配(OM,分正向和逆向)
对分词词典按词频大小顺序排列,并注明长度,降低时间复杂度。
1 | 优点:易于实现 |
逐词遍历法
这种方法是将词库中的词由长到短递减的顺序,逐个在待处理的材料中搜索,直到切分出所有的词为止。
处理以上基本的机械分词方法外,还有双向扫描法、二次扫描法、基于词频统计的分词方法、联想—回溯法等。
基于统计的分词
1 | 随着大规模语料库的建立,统计机器学习方法的研究和发展,基于统计的中文分词方法渐渐成为了主流方法。 |
主要思想:把每个词看做是由词的最小单位各个字总成的,如果相连的字在不同的文本中出现的次数越多,就证明这相连的字很可能就是一个词。因此我们就可以利用字与字相邻出现的频率来反应成词的可靠度,统计语料中相邻共现的各个字的组合的频度,当组合频度高于某一个临界值时,我们便可认为此字组可能会构成一个词语。
主要统计模型:N元文法模型(N-gram),隐马尔可夫模型(Hidden Markov Model ,HMM),最大熵模型(ME),条件随机场模型(Conditional Random Fields,CRF)等。
优势:在实际的应用中经常是将分词词典串匹配分词和统计分词能较好地识别新词两者结合起来使用,这样既体现了匹配分词切分不仅速度快,而且效率高的特点;同时又能充分地利用统计分词在结合上下文识别生词、自动消除歧义方面的优点。
N-gram模型思想
1 | 模型基于这样一种假设,第n个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。 |
我们给定一个词,然后猜测下一个词是什么。当我说“艳照门”这个词时,你想到下一个词是什么呢?我想大家很有可能会想到“陈冠希”,基本上不会有人会想到“陈志杰”吧,N-gram模型的主要思想就是这样的。
1 | 对于一个句子T,我们怎么算它出现的概率呢?假设T是由词序列W1,W2,W3,…Wn组成的,那么P(T)=P(W1W2W3…Wn)=P(W1)P(W2|W1)P(W3|W1W2)…P(Wn|W1W2…Wn-1) |
如果一个词的出现仅依赖于它前面出现的两个词,那么我们就称之为trigram。
在实践中用的最多的就是bigram和trigram了,而且效果很不错。高于四元的用的很少,因为训练它需要更庞大的语料,而且数据稀疏严重,时间复杂度高,精度却提高的不多。一般的小公司,用到二元的模型就够了,像Google这种巨头,也只是用到了大约四元的程度,它对计算能力和空间的需求都太大了。
以此类推,N元模型就是假设当前词的出现概率只同它前面的N-1个词有关。
HMM、CRF 模型思想
以往的分词方法,无论是基于规则的还是基于统计的,一般都依赖于一个事先编制的词表(词典),自动分词过程就是通过词表和相关信息来做出词语切分的决策。与此相反,
1 | 基于字标注(或者叫基于序列标注)的分词方法实际上是构词方法,即把分词过程视为字在字串中的标注问题。 |
由于每个字在构造一个特定的词语时都占据着一个确定的构词位置(即词位),假如规定每个字最多只有四个构词位置:即B(词首),M (词中),E(词尾)和S(单独成词),那么下面句子(甲)的分词结果就可以直接表示成如(乙)所示的逐字标注形式:
1 | (甲)分词结果:/上海/计划/N/本/世纪/末/实现/人均/国内/生产/总值/五千美元/ |
首先需要说明,这里说到的“字”不只限于汉字。考虑到中文真实文本中不可避免地会包含一定数量的非汉字字符,本文所说的“字”,也包括外文字母、阿拉伯数字和标点符号等字符。所有这些字符都是构词的基本单元。当然,汉字依然是这个单元集合中数量最多的一类字符。
把分词过程视为字的标注问题的一个重要优势在于,它能够平衡地看待词表词和未登录词的识别问题。
在这种分词技术中,文本中的词表词和未登录词都是用统一的字标注过程来实现的。在学习架构上,既可以不必专门强调词表词信息,也不用专门设计特定的未登录词(如人名、地名、机构名)识别模块。这使得分词系统的设计大大简化。在字标注过程中,所有的字根据预定义的特征进行词位特性的学习,获得一个概率模型。然后,在待分字串上,根据字与字之间的结合紧密程度,得到一个词位的标注结果。最后,根据词位定义直接获得最终的分词结果。总而言之,在这样一个分词过程中,分词成为字重组的简单过程。在学习构架上,由于可以不必特意强调词表词的信息,也不必专门设计针对未登录词的特定模块,这样使分词系统的设计变得尤为简单。
2001年Lafferty在最大熵模型(MEM)和隐马尔科夫模型(HMM)的基础上提出来了一种无向图模型–条件随机场(CRF)模型,它能在给定需要标记的观察序列的条件下,最大程度提高标记序列的联合概率。常用于切分和标注序列化数据的统计模型。
基于统计分词方法的实现
现在,我们已经从全概率公式引入了语言模型,那么真正用起来如何用呢?
我们有了统计语言模型,下一步要做的就是划分句子求出概率最高的分词,也就是对句子进行划分,最原始直接的方式,就是对句子的所有可能的分词方式进行遍历然后求出概率最高的分词组合。但是这种穷举法显而易见非常耗费性能,所以我们要想办法用别的方式达到目的。
仔细思考一下,假如我们把每一个字当做一个节点,每两个字之间的连线看做边的话,对于句子“中国人民银行”,我们可以构造一个如下的分词结构:
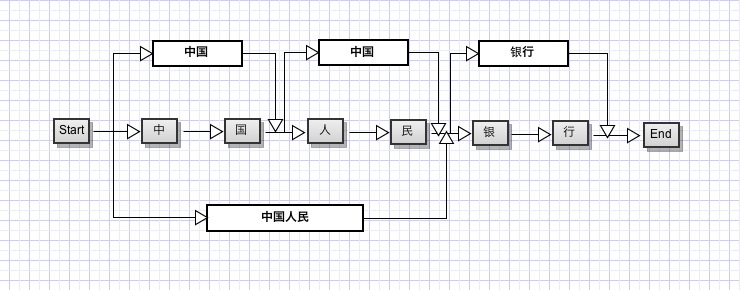
我们要找概率最大的分词结构的话,可以看做是一个动态规划问题, 也就是说,要找整个句子的最大概率结构,对于其子串也应该是最大概率的。
对于句子任意一个位置t上的字,我们要从词典中找到其所有可能的词组形式,如上图中的第一个字,可能有:中、中国、中国人三种组合,第四个字可能只有民,经过整理,我们的分词结构可以转换成以下的有向图模型:
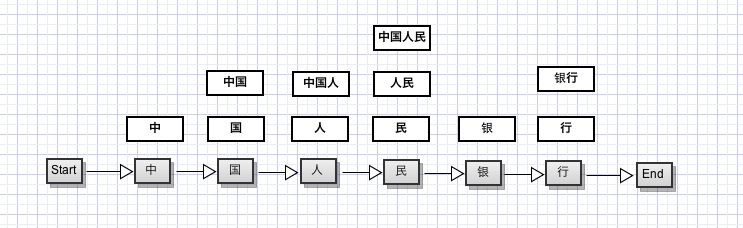
我们要做的就是找到一个概率最大的路径即可。我们假设Ct(k)表示第t个字的位置可能的词是k,那么可以写出状态转移方程:
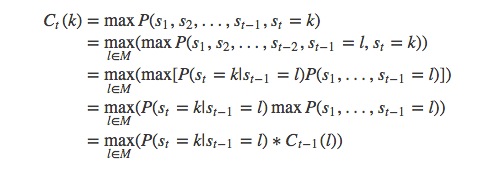
其中k是当前位置的可能单词,l是上一个位置的可能单词,M是l可能的取值,有了状态转移返程,写出递归的动态规划代码就很容易了(这个方程其实就是著名的viterbi算法,通常在隐马尔科夫模型中应用较多)。