TextRank是在Google的PageRank算法启发下,针对文本里的句子设计的权重算法,目标是自动摘要。它利用投票的原理,让每一个单词给它的邻居(术语称窗口)投赞成票,票的权重取决于自己的票数。这是一个“先有鸡还是先有蛋”的悖论,PageRank采用矩阵迭代收敛的方式解决了这个悖论。TextRank也不例外:
PageRank的计算公式:
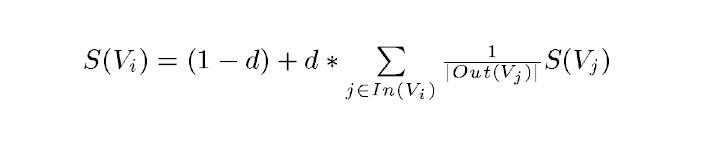
TextRank的计算公式:
正规的TextRank公式在PageRank的公式的基础上,引入了边的权值的概念,代表两个句子的相似度。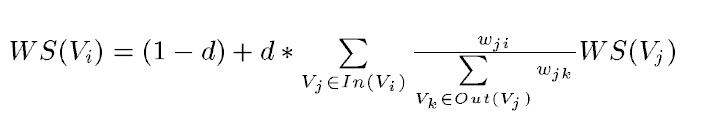
但是很明显我只想计算关键字,如果把一个单词视为一个句子的话,那么所有句子(单词)构成的边的权重都是0(没有交集,没有相似性),所以分子分母的权值w约掉了,算法退化为PageRank。所以说,这里称关键字提取算法为PageRank也不为过。
Java实现
先看看测试数据
1 | 程序员(英文Programmer)是从事程序开发、维护的专业人员。 |
我取出了百度百科关于“程序员”的定义作为测试用例,很明显,这段定义的关键字应当是“程序员”并且“程序员”的得分应当最高。
首先对这句话分词,这里可以借助各种分词项目,比如HanLP分词,得出分词结果:
1 | [程序员/n, (, 英文/nz, programmer/en, ), 是/v, 从事/v, 程序/n, |
然后去掉里面的停用词,这里我去掉了标点符号、常用词、以及“名词、动词、形容词、副词之外的词”。得出实际有用的词语:
1 | [程序员, 英文, 程序, 开发, 维护, 专业, 人员, 程序员, |
下面是代码实现的关键:
之后建立两个大小为5的窗口,每个单词将票投给它身前身后距离5以内的单词(中括号的词排名不分先后,但原始分词顺序不可以打乱):1 | {开发=[专业, 程序员, 维护, 英文, 程序, 人员], |
然后开始迭代投票,代码没什么难的,就是按照原论文算法过程简单的实现了一遍,这里简单给个注释,省得以后看起来麻烦:
1 | for (int i = 0; i < max_iter; ++i) //最外层条件是算法设定的最大迭代次数 |
排序后的投票结果:
1 | [程序员=1.9249977, |