在有迭代计算的领域,Spark 的计算速度远远超过 MapReduce,并且迭代次数越多,Spark 的优势越明显。这是因为 Spark 很好地利用了目前服务器内存越来越大这一优点,通过减少磁盘 I/O 来达到性能提升。它们将中间处理数据全部放到了内存中,仅在必要时才批量存入硬盘中。
具体来讲,学习任何知识都必须先了解这个知识的历史,才能更深刻的理解。同样的,spark宣称比hadoop快又好,那么后者差在哪里呢?
hadoop经历过1.0和2.0的时代,所面临的问题一直以来最主要的就是中央集权问题。1.0时代的主要组织架构分为两个部分:
数据进程
NameNode 和 DataNode
NameNode是 HDFS (hadoop file system)的主控服务器。它指挥slave的DataNode守护进程执行低level的IO任务。
1 | It keeps track of how your files are broken down into file blocks, which nodes store those blocks, and the overall health of the distributed filesystem. |
Secondary NameNode 并非NameNode的backup,而是部分承担了NameNode的工作。因此NameNode是单节点的(single point of failure)。
1 | 在超大规模hadoop系统中,Namenode往往负载很重,容易失败。因此facebook,cloudera都修改了hadoop架构来减少系统失败几率。 |
如果拿户籍管理来比喻的话,namenode就相当于整个hadoop File system的户口簿,有且仅有一份,datanode就是各个区县自治区。如果户口簿丢了,那一切管理工作就都无从谈起了。
计算进程
JobTracker 和 TaskTracker
和用于storage的进程一样,用于计算的进程也使用了master/slave架构。JobTracker负责监控所有的mapreduce job,如果一个task失败了,它负责重启一个。在哪个datanode重启,这个有一定的策略。同时JobTracker还负责集群资源管理,如是否有新节点加入集群,是否有节点离开等等。
Each TaskTracker is responsible for executing the individual tasks that the JobTracker assigns. Although there is a single TaskTracker per slave node, each TaskTracker can spawn multiple JVMs to handle many map or reduce tasks in parallel.
TaskTracker甚至可以同时执行mapper和reducer
JobTracker就好比明太祖朱元璋一样,是个劳模,事无巨细的安排好。底下的官员就像TaskTracker一样,虽然它叫tracker,但是实际操作人是它。
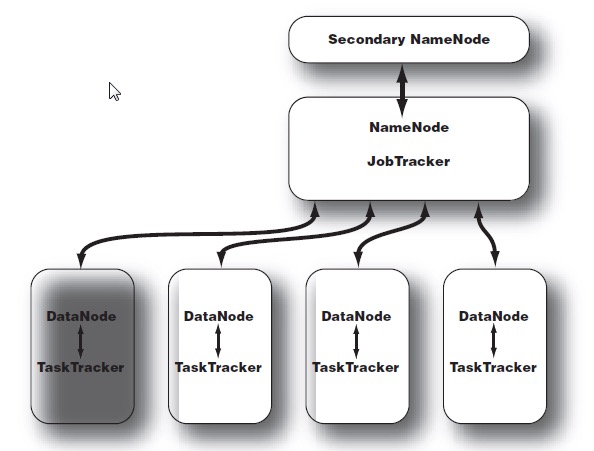
除了上面的架构上的不足以外,还有一个容易忽略的地方就是1.X版本中,资源利用率是很低的。Tasktracker使用slot划分本节点上的资源量。一个Task在获得slot之后才可以运行。slot分为mapSlot和reduceSlot,分别对应mapTask和reduceTask。有时候会因为作业刚启动的时候,导致MapTask很多,而reduceTask没有调度的情况,而别的线程也无法使用空闲的reduceSlot资源。
如果说2.0有什么创新的话,我觉得在于改良而不在于革命,它依旧突破不了那一套旧的根本,如果不是将各个模块剥离, 同时将控制权交出去 ,以高效运算为中心,那这套系统早就已经被淘汰了。新的框架架构如下:
1、通过YARN实现资源的调度与管理,从而使Hadoop 2.0可以运行更多种类的计算框架,如Spark等。
1 | 以前是只能自己写MR接口使用,现在心胸更开阔一点了,不open不行,大家不用了就不好了。 |
2、实现了NameNode的HA方案,即同时有2个NameNode(一个Active另一个Standby),如果ActiveNameNode挂掉的话,另一个NameNode会转入Active状态提供服务,保证了整个集群的高可用。
1 | 实在想不出1.0不备份namenode是为什么 |
3、实现了HDFS federation,由于元数据放在NameNode的内存当中,内存限制了整个集群的规模,通过HDFS federation使多个NameNode组成一个联邦共同管理DataNode,这样就可以扩大集群规模。
1 | 通过namenode的扩展,实现了整个集群的规模扩展 |
4、Hadoop RPC序列化扩展性好,通过将数据类型模块从RPC中独立出来,成为一个独立的可插拔模块。
Yarn
纵观说来,yarn的发明是2.0最具颠覆性的功能,它是一个通用的资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
1 | 总结来说,yarn对计算进程端进行了大刀阔斧的改革,而数据进程则仅仅进行了HA |
那么Yarn的设计哲学是什么呢?
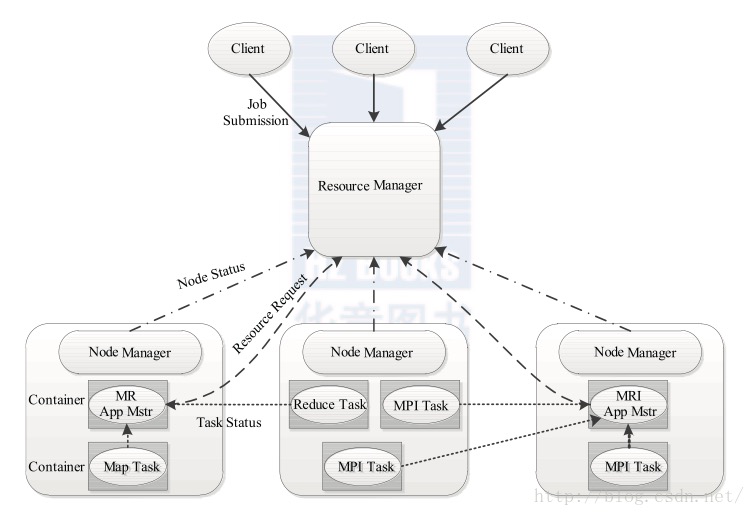
YARN的基本设计思想是将Hadoop 1.0中的JobTracker拆分成了两个独立的服务:一个全局的资源管理器ResourceManager和每个应用程序特有的ApplicationMaster。其中ResourceManager负责整个系统的资源管理和分配,而ApplicationMaster负责单个应用程序的管理。
1 | 这种模式的核心思想也是放权,从JobTracker的事无巨细,到转变为ResourceManager,同时扶持多个ApplicationMaster向ResourceManager汇报。 |
Hadoop两代版本的比较就到此为止,各个组件内部是如何工作的我们暂且不表。未来可以细分讨论一下。接下来想说的是spark这个具有革命性的东西。为什么前文说Hadoop并没有真正的进行革命,因为它想用它自己的那一套MR的方式,维护着统治,纵然有了分权等先进制度,但是无异于洋务运动,治标不治本。
Spark的优化如下:
减少磁盘IO
这个不用废话,两个流程图就可以明白。
1 | MRv1: map => 磁盘 => reduce => 磁盘 |
增加并行度
这个涉及到RDD的宽依赖和窄依赖,不同的依赖可以分为不同的stage,stage之间可以串并联运行。串并的程度取决于系统的资源。
避免重复计算
得益于RDD的DAG设计以及checkpoint和cache,重启失败job的时候可以避免重复计算。
可选shuffle排序
Hadoop的MR在shuffle之前有着固定的排序操作。在spark中可以自己选择在map端排序还是在reduce端排序。
灵活高端的内存管理策略
spark由于是基于内存的,所以内存管理的策略就尤为重要。这里不做赘述后面可以深入研究一下。