Spark框架基本概念
所谓的Spark框架基本概念都是围绕着RDD衍生出来的:
- DAG: 用有向无环图来表示RDD之间的血缘关系
- Partition: RDD的分区数,Spark根据partition的数量确定task的数量
- 窄依赖: 子RDD依赖父RDD的固定partition
- 宽依赖: 子RDD对父RDD所有的partition都有可能依赖
- JOB:用户提交的作业,当RDD以及其DAG被提交到DAGScheduler调度后,后者将所有的RDD的transformation和action视为一个JOB
- Stage:这个是job执行时候的概念,根据宽窄依赖来区分
- Task:每个job在每个stage内,都会按照RDD的Partition的数量创建多个Task。一个rdd分成几个partition,则有几个task
- Shuffle:所有MR框架的核心执行阶段,用来连接map和reduce。
spark设计思想
前文也说过,Hadoop2.X并没有对自己底层mr框架的难用有任何反思,所以spark并没有继承这一坑,转而自开发了一套针对RDD转化和执行的API。这就使得spark的使用极其丰富了。下面我们聊聊spark的设计逻辑哲学思想。
一个完整的组织,需要有明晰的结构划分,才能发挥最大的作用,Spark也不能例外。历史上那些没有高度统一的,层级分明的框架都已经被淘汰了。同样的,一个组织架构要有自己的使命,才能清楚的知道自己该做什么,能做什么,如何做好。
1 | Apache Spark™ is a unified analytics engine for large-scale data processing |
官网上已经为其理清了血统,作为一个统一的大规模数据处理分析引擎,我们可以知道,它的核心功能一定分为以下几个部分。
基础设施
基础设施顾名思义,乃是Spark整个基石的基础,包括sparkConf,内置RPC(以前使用Actor,后来用Netty自己实现了),事件总线,度量系统。
为什么这些组成了Basic Instructure,可以想象一下,SparkConf就相当于一张饭票一样,里面记录了一个spark JOB所需要的各种资源清单,包括不局限于CPU,内核数等等,没有这张清单,你就无法获得资源,运行就无从谈起了。
RPC(Remote Procedure Call),这个不用多讲了,Spark基于Hadoop的存储架构,可以支持分布式的大规模运算,没有RPC的话,集群间的通信就无法实现,可以说这个是spark大规模计算实现的基础,单机你才多点儿数据。
事件总线,RPC可以理解为不同机器间的通信设施,而时间总线可以理解为SparkContext内部各个组件使用事件监听模式。或者可以粗暴的理解为一个线程调度系统,具体想要深入的了解事件总线,推荐到这个地方进行仔细的参考。也就是说,它是spark内部能够有条不紊运行的基础。
度量系统,这个对大家来说比较陌生,但是它也十分重要(既然被放到了基础设施中)。但是它却是一个实实在在的监控系统。
它大概分成了一下几个模块:
Instance:指定了度量系统的实例名。Spark按照Instance的不同,区分为Master、Worker、Application、Driver和Executor;
Source:指定了从哪里收集度量数据,即度量数据的来源。Spark提供了应用的度量来源(ApplicationSource)、Worker的度量来源(WorkerSource)、DAGScheduler的度量来源(DAGSchedulerSource)、BlockManager的度量来源(BlockManagerSource)等诸多实现,对各个服务或组件进行监控。
Sink:指定了往哪里输出度量数据,即度量数据的输出。Spark中使用MetricsServlet作为默认的Sink,此外还提供了ConsoleSink、CsvSink、JmxSink、MetricsServlet、GraphiteSink等实现。
那么基于此,就能够知道,spark那些比较精细的统计数据,是基于什么实现的了。
以上几个部分,就是spark基础设施的全部内容,涵盖了通信、资源配置、系统级别的监控。可以感受的到,这些基础设施之所以称之为都是spark内部的架构。
SparkContext
Context是上下文的意思,那么sparkContext顾名思义就是spark上下文,可以说它包罗万象,不仅仅有我们上面提到的基础设施,还包括了外部的存储体系,文件系统,等等。开发者仅仅需要使用sparkContext提供的API即可完成功能开发。它是一个总的环境池,就像一条大河的源头一样,一切都从这里发生。
SparkEnv
Env是运行时环境,它包含了task所要运行的各种组件
储存体系
spark优于hadoop就是得利于它的存储设计,这个已经老生常谈, 这里就不扩展开讲述。
调度系统
调度系统要和刚刚的度量系统区分开来,后者是用于内部数据流程的精细监控。而前者主要分DAGScheduler和TaskScheduler,这两个Schedulor也是在SparkConf中。两者也有不同的分工,从级别上来讲,他俩还不负责实操,DAG感觉就像产品经理,不断地给Task提需求(创建job,划分stage、给stage创建task),同时这个需求还不能总提,你得控制节奏,所以要批量提交task。TaskScheduler也不是省油灯,它也不干活 ,它只是负责指挥调度Excutor,真正的实操是在Excutor上面。
计算引擎
整个计算引擎,除了我们了解的最普遍的MR以外,还涉及到了比较精细粒度的内存管理和执行控制,这里具体不表,可以单独深入的了解一下。
以上就是spark大体框架的一个比较哲学的分析。后三部分是我们基于直观感受能够想到的,而前三个部分正是基础中的基础。
Spark的物理架构
以上我们以手术刀般精准的角度去剖析了spark体系的边边角角,但是对spark的计算流程谈的不甚详细,同时上面提到的这些架构,分布在机器的哪些位置,还不清楚。所以再花一点篇幅,写一下我自己对计算流程的理解和对物理架构的介绍。
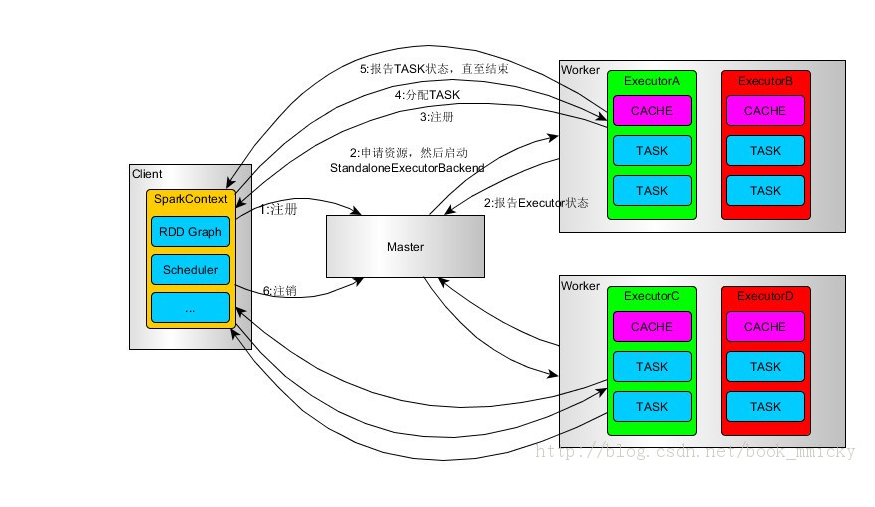
生活中办事儿,需要中间人、老司机。那spark在提交作业的时候,也不是想交就能交的上去的,也得有老司机带路。这个老司机就是driver,那driver干了些啥呢?当我们的应用程序将代码提交给她后,它大概有以下几件事情要做:
- RpcEnv向集群管理器(Cluster Manager)注册应用(也就是你写的Application,跟挂号是一个道理,你不在Cluster Manager注册,集群是不会知道要运行你这个程序的)
- 并且注册后,我们的集群管理员会根据你的提交清单(也就是你sparkconf记录的东西)来分配资源
- 并且在worker上启动CoarseGrainedExecutorBackend进程(这么一大串太装逼了,你就知道它用来创建executor即可)。要注意,这个启动的过程是一个双向反馈的过程,它会直接通过RpcEnv向老司机注册已经申请到的Executor的信息,这样老司机才能有办法跟我们交差,不然我们岂不是白白委托它了。
- 同时,下游的TaskScheduler也会记录这些Executor的信息,它的角色就相当于包工头一样,当然要记录组织分配下来的劳力。
- SparkContext,前文说过了,母亲河,会将RDD的各种转换关系构建成为DAG,然后DAG会被传给DAGScheduler。
- 后者把它划分为不同的stage,然后根据每个stage内的RDD的Partition数量创建Task,批量提交给TaskScheduler。
- 包工头对批量的Task进行指挥,指挥方式有FIFO或者FAIR,按既定方针送给底层民工Executor执行。
1 | SparkContext在RDD转换开始之前,使用BlockManager和BroadcastManager将任务的Hadoop配置进行广播。这样就确保了每台机器都能够按既定方针办事 |
上述过程形在流程,而实有三个,Driver,SparkContext,Cluster Manager。而我们对第三者关注的并不是太多,实际上它是我们熟悉的面孔,常用的管理者就是——Yarn。它是Driver和Worker节点连接者。而Worker节点,就是民工所在地,为了民工好干活,Store存储也在Worker上,即: